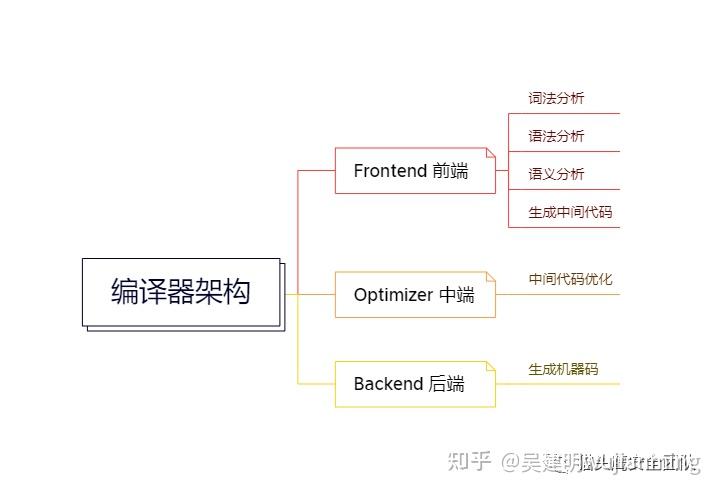
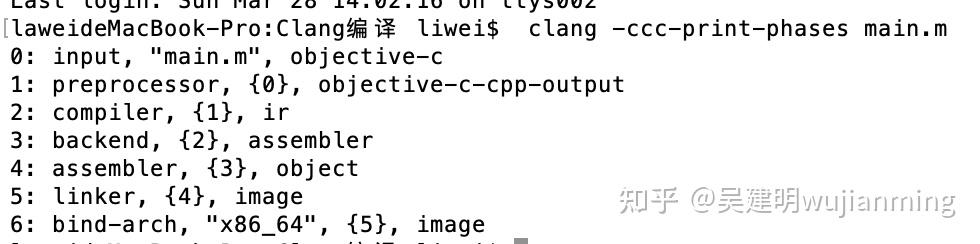
可以看到,一共有7个阶段,它们分别表示的含义如下:
o 0:input,输入源代码文件
o 1:preprocessor,预处理阶段,头文件的导入、宏的替换都是在这个阶段进行处理
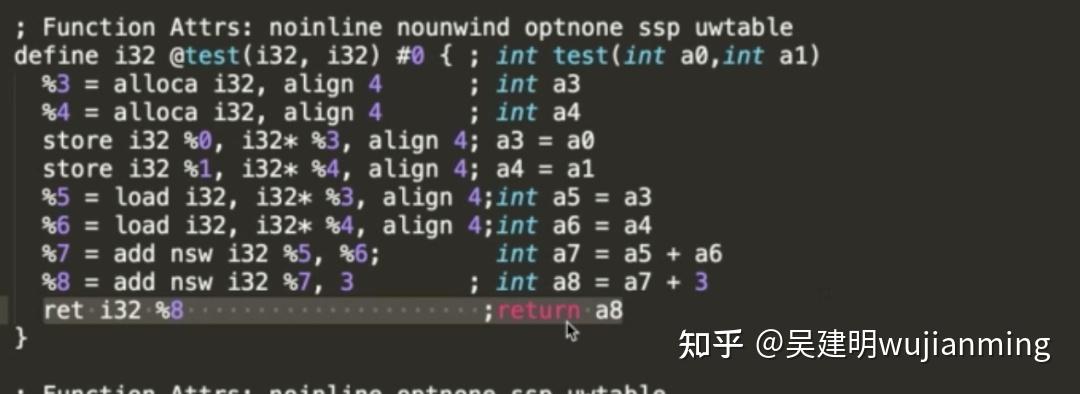
o 2:compiler,编译阶段,词法分析、语法分析、语义分析、检查源代码是否存在错误,最后生成IR代码,并交给下面的后端
o 3:backend,后端,这里LLVM 会通过一个一个的pass去优化,每个pass做一些事情,最终生成汇编代码
o 4:assembler,生成object目标文件,也就是我们熟知的.o文件。
o 5:linker,链接,将各个.o文件以及需要的动态库和静态库链接起来,最终生成可执行文件Mach-o
o 6:bind-arch,针对不同的架构,会生成对应的Mach-o可执行文件。
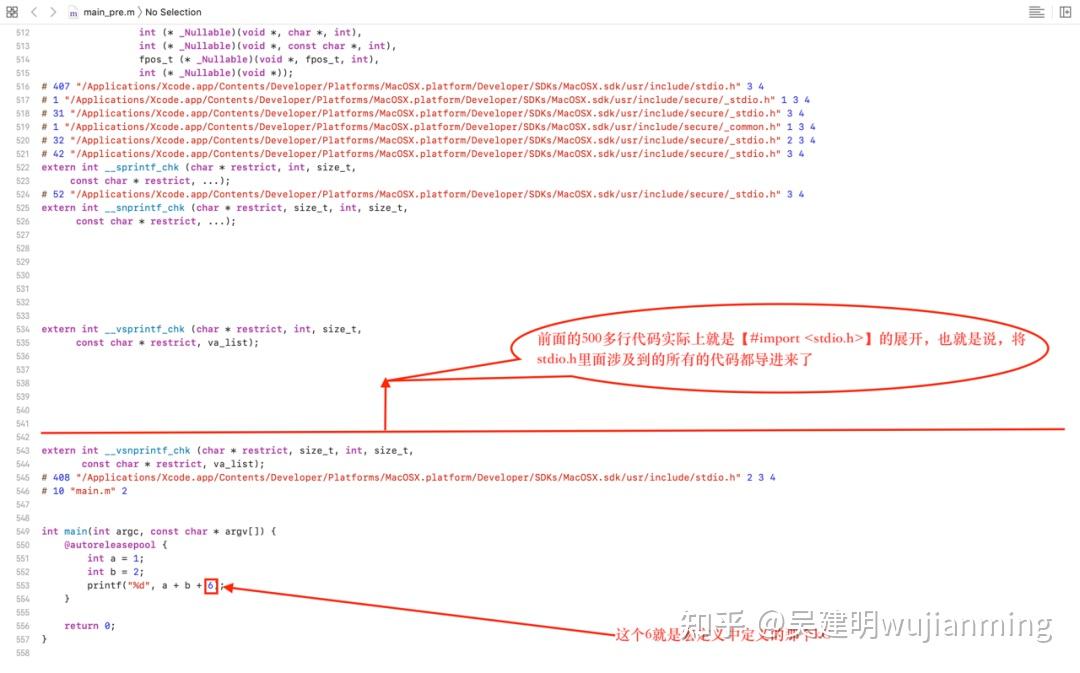
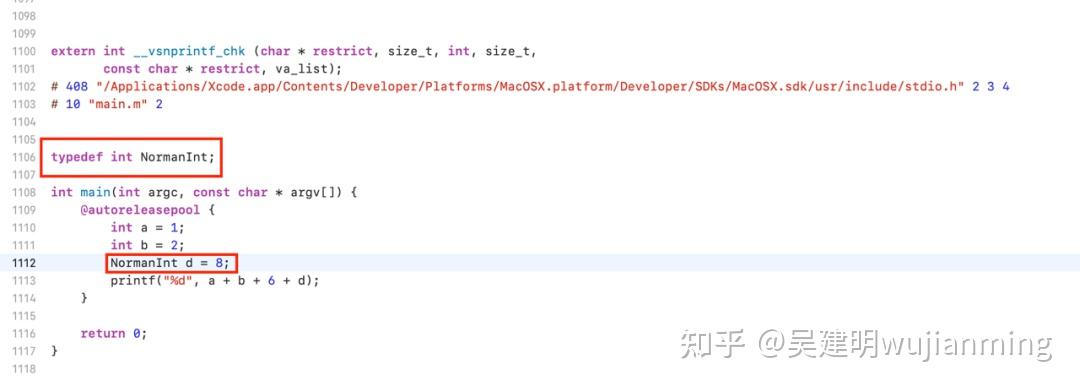
1,预处理阶段
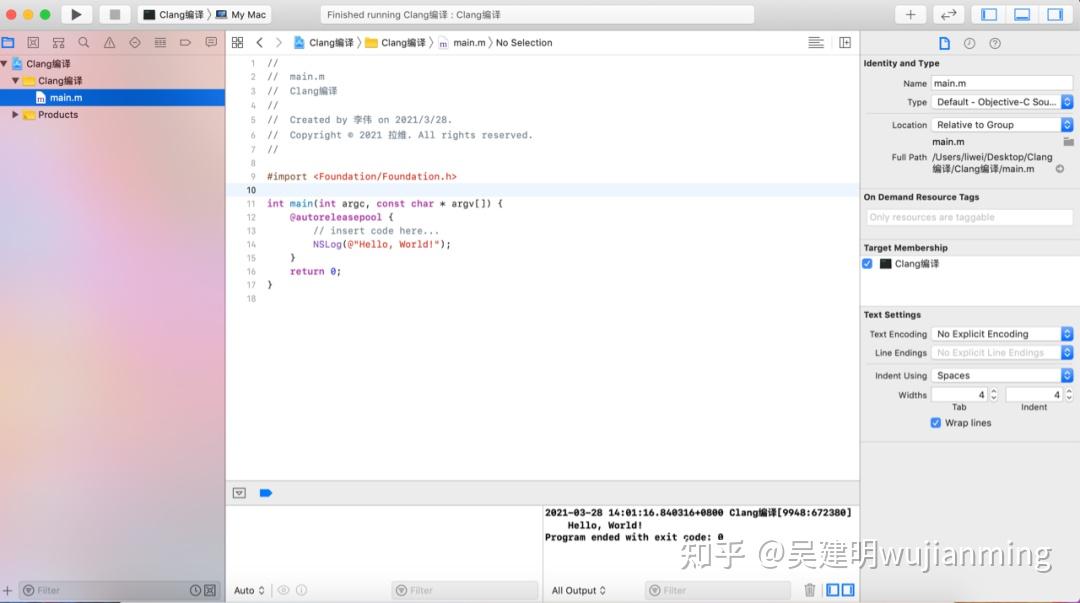
首先main.m中输入一些内容:


 发表于 2023-8-4 15:36:51
发表于 2023-8-4 15:36:51